University of Alaska Fairbanks
Geophysical Institute
Beyond the Mouse 2010 - The geoscientist's computational chest.
10. Live Coding: Applied Unix Tools
Donald E. Knuth
Lecture
No lecture slides, this website is the summary. You'll find all necessary scripts and the example database in this archive as tar.gz and zip.
Objective
The goal of this exercise is to automate the extraction of 5 min GPS positions from a given database for various GPS stations. Minor changes in a previously used Matlab script should allow us to automatically plot these data and save the figures.
Data
Our example database contains 8 columns: station-id | day of year | Ref-lat | Ref-lon | Ref-height | lat | lon | height, where 'ref' means
'reference' but this is not very important. Here is an excerpt from the database (Bezy2009.dat):
(column: 1 2 3 4 5 6 7 8 )
BZ09 347.00000000 55.982467208 160.581416741 2539.8446 55.982466363 160.581417608 2539.3093
BZ06 347.00000000 55.899597940 160.550529524 1715.9546 55.899597537 160.550530545 1715.4075
BZ04 347.00000000 55.932567373 160.553716243 1671.4151 55.932566574 160.553717359 1670.7805
BZ03 347.00000000 55.958141918 160.556598697 2071.7480 55.958140810 160.556599910 2071.1410
BZ01 347.00000000 55.978378714 160.532566368 1998.8059 55.978377766 160.532567265 1998.1650
BZ09 347.00347222 55.982467208 160.581416741 2539.8446 55.982466421 160.581417721 2539.3144
BZ06 347.00347222 55.899597940 160.550529524 1715.9546 55.899597472 160.550530596 1715.4071
BZ04 347.00347222 55.932567373 160.553716243 1671.4151 55.932566597 160.553717350 1670.7774
BZ03 347.00347222 55.958141918 160.556598697 2071.7480 55.958140821 160.556599954 2071.1364
BZ01 347.00347222 55.978378714 160.532566368 1998.8059 55.978377777 160.532567326 1998.1603
BZ09 347.00694444 55.982467208 160.581416741 2539.8446 55.982466364 160.581417762 2539.3156
BZ06 347.00694444 55.899597940 160.550529524 1715.9546 55.899597474 160.550530624 1715.4122
BZ04 347.00694444 55.932567373 160.553716243 1671.4151 55.932566585 160.553717396 1670.7777
BZ03 347.00694444 55.958141918 160.556598697 2071.7480 55.958140875 160.556599993 2071.1293
For each station we are interested in colums 2,6,7, and 8; namely the time for which a certain lat, lon, and height were determined.
Step 1: Extract data for one station
Let's start fairly simply and select all the data we have for one station, say BZ09. We can do this using the
tools grep and awk. grep will allows us to decimate the rows to rows only
containing the string 'BZ09' which obviously is a unique identifier. On the command line, call:
$> grep BZ09 Bezy2009.dat
The resulting output should be similar to this:
BZ09 360.98263889 55.982467208 160.581416741 2539.8446 55.982466743 160.581417701 2539.2673
BZ09 360.98611111 55.982467208 160.581416741 2539.8446 55.982466747 160.581417731 2539.2629
BZ09 360.98958333 55.982467208 160.581416741 2539.8446 55.982466823 160.581417750 2539.2598
BZ09 360.99305556 55.982467208 160.581416741 2539.8446 55.982466877 160.581417780 2539.2548
BZ09 360.99652778 55.982467208 160.581416741 2539.8446 55.982466901 160.581417808 2539.2472
Now we can pipe this output into awk to select the rows we want and redirect the output into a new file
BZ09.dat
$> grep BZ09 Bezy2009.dat | awk '{print $2,$6,$7,$8}' > BZ09.dat
Here are the last 5 lines of the new file BZ09.dat:
$> tail -n 5 BZ09.dat
360.98263889 55.982466743 160.581417701 2539.2673
360.98611111 55.982466747 160.581417731 2539.2629
360.98958333 55.982466823 160.581417750 2539.2598
360.99305556 55.982466877 160.581417780 2539.2548
360.99652778 55.982466901 160.581417808 2539.2472
You see that these data are the same as the ones given above. Excellent! Let's put this into a shell script, say
extract_llh.sh:
#!/bin/tcsh
grep BZ09 Bezy2009.dat | awk '{print $2,$6,$7,$8}' > BZ09.dat
(Don't forget to set the premissions for this file to executable: > chmod +x extract_llh.sh.)
This one line of code combines two extremely powerful tools for data handling as well as two very important concepts
(piping, output redirection) for shell scripting. If you're doing any data handling in Unix these concepts will
be used over and over again and you should familiarize yourself with these! PLAY WITH THEM!
The above script is a rather static, i.e. too specific, non-general, shell script that works on exactly one database using one station. We'll change that in the next step.
Step 2: Extract data for all stations in the database
To work on all stations that have data in the database, we could just manually extract the station names.
What, though, if we want to work on various databases which hold data for differently named stations? Well, we could
try to automatically create the list of stations from the database using awk and sort:
$> awk '{print $1}' Bezy2009.dat | sort -u
BZ01
BZ03
BZ04
BZ06
BZ09
Here, awk extracts the first column of the database - the station names. sort -u will
output only the first occurence of a string it is being handed, i.e. we get a unique list. Sweet. In our shell
script we will run the above command inside backticks to have it executed in a subshell. The resulting station
list is being saved to a variable sta_list:
#!/bin/tcsh
# define the database we want to work on
set data = Bezy2009.dat
# get a unique station list from our database
set sta_list = `awk '{print $1}' $data | sort -u`
# iterate over the station list and create a new data file for each site
foreach sta ( $sta_list )
echo "Working on station $sta ..."
grep $sta $data | awk '{print $2,$6,$7,$8}' > ${sta}.dat
end
I incorporated a few more changes here. First, I created a variable data which holds the name of the database
we want to work on. I do this, because the database now comes up in two places and at some point later on you'll certainly
forget to change it in one place. This creates all sorts of havoc and confusion, cussing and swearing, and I want to prevent
that. Second, I also created a loop over the values in sta_list which creates data files for all GPS stations
we found in the database.
Step 3: Allow to set the database on the command line
Another step of generalization in our script now is to get rid of the definition of the database Bezy2009.dat.
Being able to define this when calling the script on the command line certainly adds a lot of flexibility, so we'll
just do this. We gotta be careful though, since now the user has a way to interact with our script which usually means
trouble. Therefore, we need to add a few more tests: Did the user give a command line argument at all? Did
the user give a command line argument that exists? See comments in script:
#!/bin/tcsh
# The $# variable contains the number of command line arguments given
# Since we want exactly one argument, we test for this
if( $# != 1) then
echo "USAGE: $0 DATABASE"
exit 1
endif
# define the database we want to work on, first command line argument
set data = $1
# now we need to check whether the file exists, or else give an error:
if (-e $data) then
# tell the user what we're working on.
echo "Using database: $data"
# get a unique station list from our database
set sta_list = `awk '{print $1}' $data | sort -u`
# iterate over the station list and create a new data file for each site
foreach sta ( $sta_list )
echo "Working on station $sta ..."
grep $sta $data | awk '{print $2,$6,$7,$8}' > ${sta}.dat
end
else
echo "$0 ERROR: File '$data' does not exist."
exit 2
endif
Recall that $0 is the command name as given on the command line, $1 is the
first argument on the commandline. Here are a few use cases; the first one with no arguments, the second one
with a file that doesn't exists, and the last one with our trusty database:
$~> extract_llh.sh
USAGE: ./extract_llh.sh DATABASE
$~> extract_llh.sh bla.dat
./extract_llh.sh ERROR: File 'bla.dat' does not exist.
$~> extract_llh.sh Bezy2009.dat
Using database: Bezy2009.dat
Working on station BZ01 ...
Working on station BZ03 ...
Working on station BZ04 ...
Working on station BZ06 ...
Working on station BZ09 ...
That's a pretty useful script; with only three lines of code we can make it amazing.
Step 4: Plot data for each site using Matlab
MATLAB offers to run at the commands defined at the command line with the "-r" option:
$~> matlab -nojvm -nosplash -r "disp 'hello remote matlab'; exit;"
The -nojvm -nosplash flags prevent Matlab from starting the fancy visual interface
and prompting the splash screen, respectively. The above call will result in:
< M A T L A B (R) >
Copyright 1984-2008 The MathWorks, Inc.
Version 7.7.0.471 (R2008b)
September 17, 2008
To get started, type one of these: helpwin, helpdesk, or demo.
For product information, visit www.mathworks.com.
hello remote matlab
It will simply execute the disp command and display hello remote matlab. After this
the next command can be executed; here it is exit to shutdown MATLAB.
To make use of this functionality and get our data automatically plotted, I altered the Matlab script plot_stations.m which we created in Lab 04. I defined it as a function which takes the station cell array as input argument (check code to see what I mean). This will enable us to call this function from the command line:
$~> matlab -nojvm -nosplash -r "plot_stations({'BZ09', 'BZ01'}); exit;"
It should be easy to see that we can create a string that defines the cell array we have to hand to
plot_stations:
#!/bin/tcsh
# The $# variable contains the number of command line arguments given
# Since we want exactly one argument, we test for this
if( $# != 1) then
echo "USAGE: $0 DATABASE"
exit 1
endif
# define the database we want to work on, first command line argument
set data = $1
# now we need to check whether the file exists, or else give an error:
if (-e $data) then
# tell the user what we're working on.
echo "Using database: $data"
# get a unique station list from our database
set sta_list = `awk '{print $1}' $data | sort -u`
# define empty string which will eventually hold all stations to define
# a matlab cell array
set matlab_cell = " "
# iterate over the station list and create a new data file for each site
foreach sta ( $sta_list )
echo "Working on station $sta ..."
grep $sta $data | awk '{print $2,$6,$7,$8}' > ${sta}.dat
# append the current station to the matlab_cell string; $sta needs to be
# in single quotes to indicate that it's a string in Matlab. If the
# single quotes aren't given, MATLAB will think, e.g. BZ01 is a variable
set matlab_cell="$matlab_cell '$sta'"
end
# once all the data files are created, we can call MATLAB to update the plots
# Note that $matlab_cell needs curly braces around it, to indicate it's a
# cell array.
matlab -nojvm -nosplash -r "plot_stations( { $matlab_cell }, 1 ); exit; "
else
echo "$0 ERROR: File '$data' does not exist."
exit 2
endif
In your directory you'll now find data files for all the GPS stations that end in .dat
and the figures which end in .eps for printing and .png for web-publishing
(click on figures to enlarge):
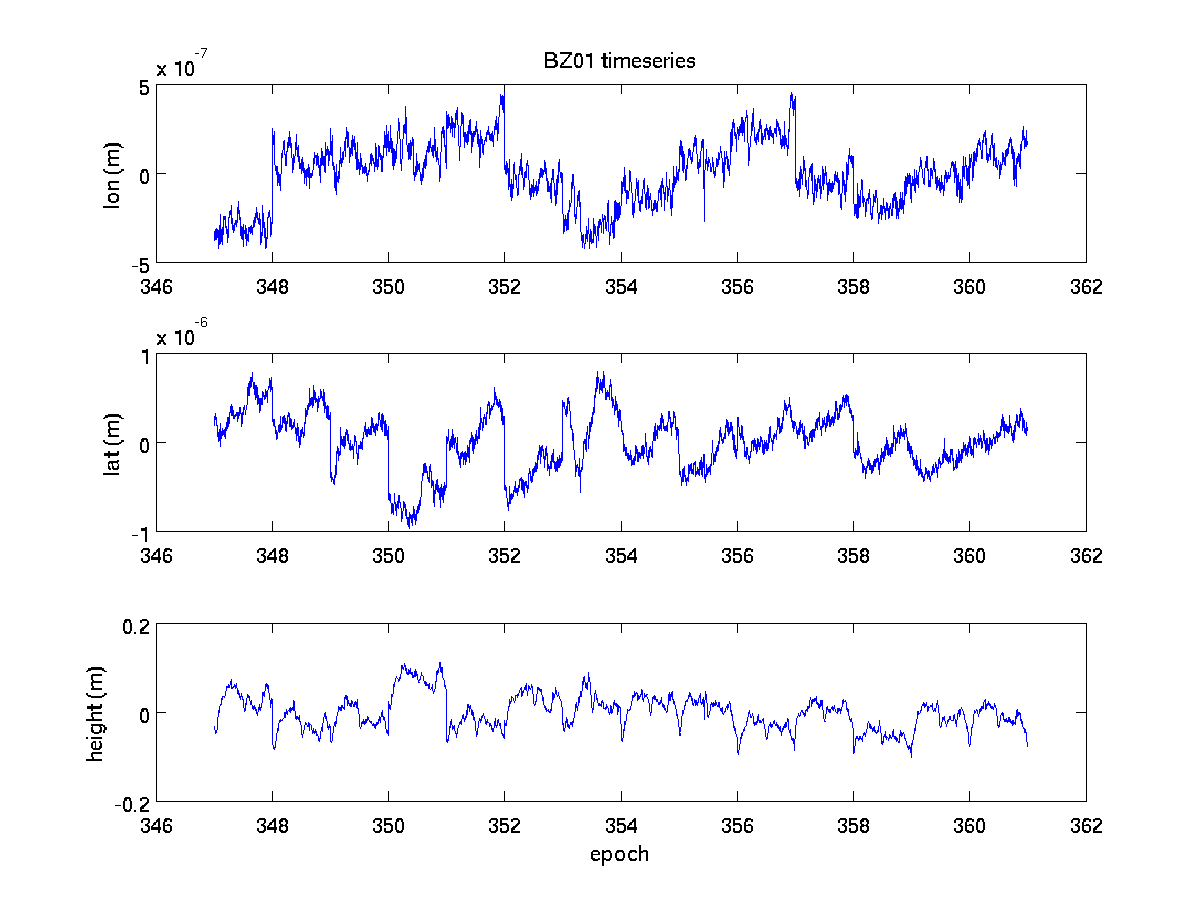
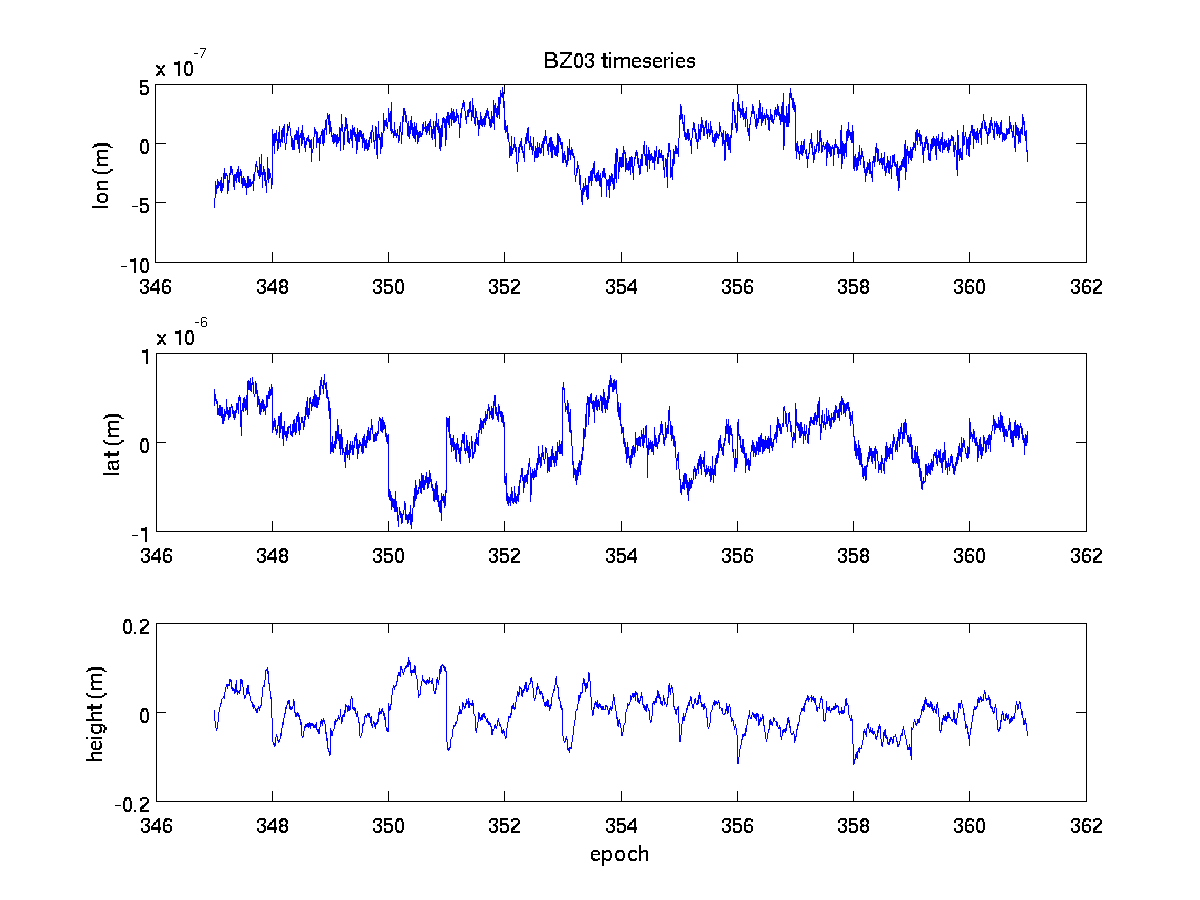
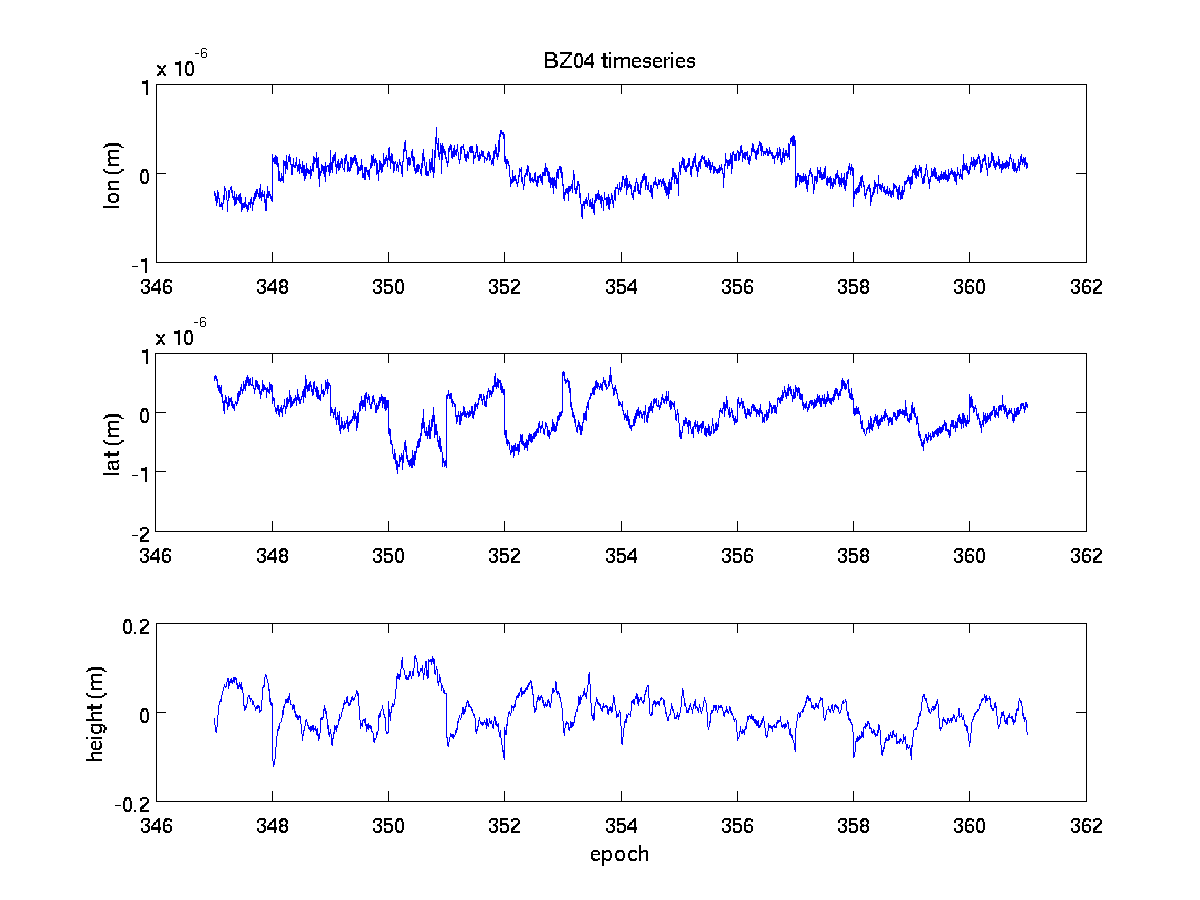
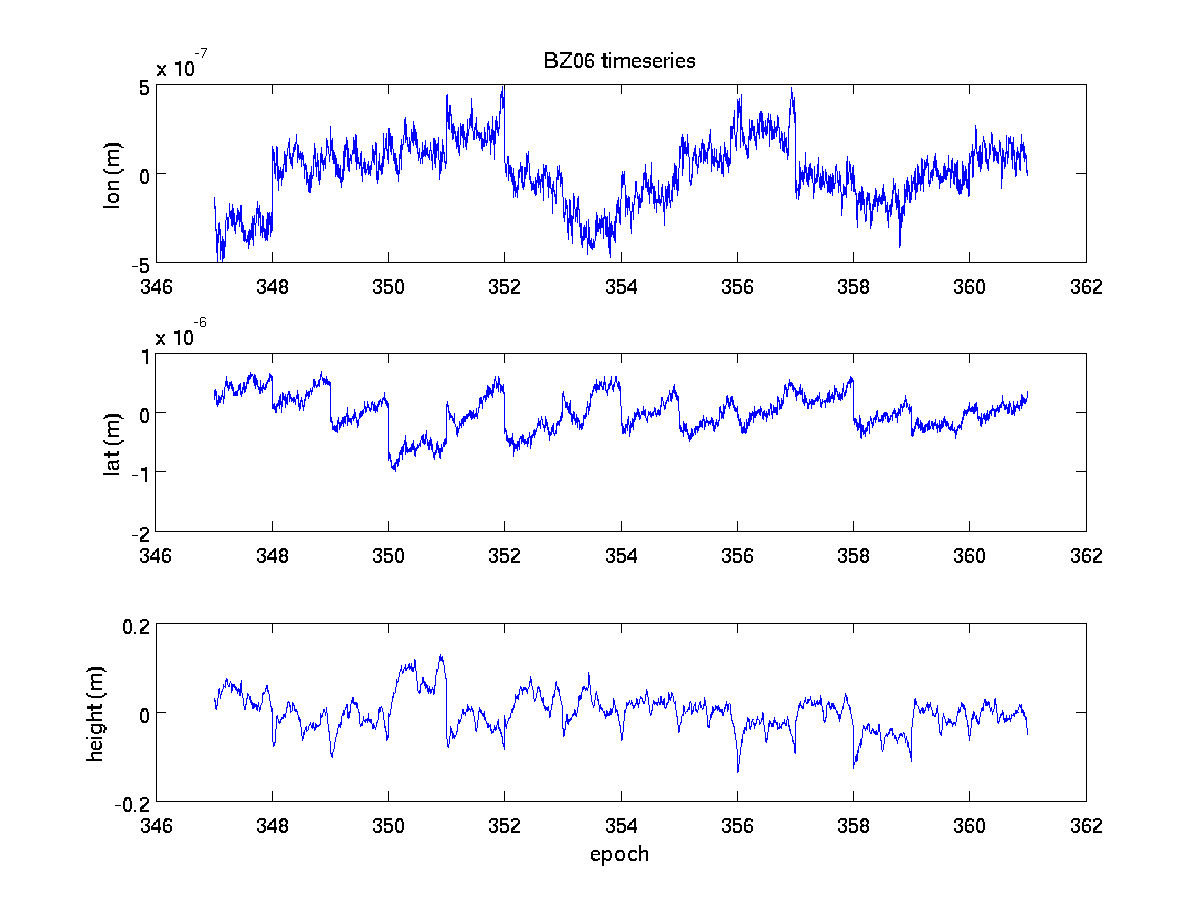

ronni <at> gi <dot> alaska <dot> edu | last changed: Nov 15, 2010